
我做了一個自動化的 Jazz 演出平台
在之前的文章 AI Agent 搭配 Playwright MCP,讓 AI 幫你操作網站 中,嘗試了 Facebook 的活動爬蟲功能,其實當時就是在實作這個專案中的固定 Facebook 活動爬蟲,而這個成品就是我的 Taiwan Jazz Info 網站。

這個網站其實我想要做的事情有以下,期望能為我所愛的台灣爵士增加更多曝光與整合平台:
- 整合台灣爵士場館資訊
- 自動化抓取場館演出資訊
N8N 搭配 AIAgent 自動化流程設計
目前台灣的場館中比較具有規模的是 Sappho 以及 Blue Note 這兩間,或者說這兩間也是開設比較久,有經歷到網路時代的變遷,也因此 只有這兩間場館才有架設自己的 Website,並且會固定更新演出資訊。
其他場館大多透過 Facebook 來新增活動,這也是造成傳統爬蟲的困難,但在今天我們就可以搭配 AI Agent 與 Playwright MCP 來解決這個問題。關於網站的建置與 HTML Calendar 就不多太著墨了,這篇文章主要把焦點放在透過 N8N 自動抓取 Facebook 上的活動頁面,也是我今天的挑戰,並且存入 Google Sheet 中(終究還是為了方便編輯)。
以下是我的 n8n 的設計,來製作一個自動化流程,能夠每週觸發自動抓取指定 Facebook 粉專的活動
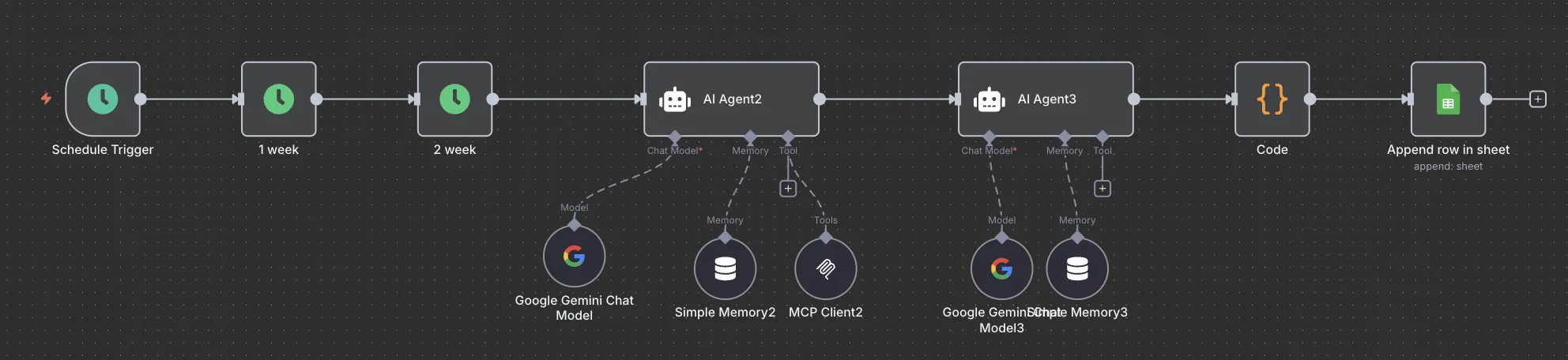
- Trigger 與時間設定
- AI Agent - 透過 Playwriht 網頁爬蟲使用
- AI Agent - 整理爬蟲資料
- Script 與 Google Sheet - 整理 AI 產出資料寫入 Google Sheet
1. Trigger 與時間設定
第一個節點是 trigger,我直接使用 cronjob 設定在 0 1 * * 0 ,在每個禮拜天的 1 點觸發。
第二、三個節點其實是為了決定我 Facebook 要抓取的日期,用變數 {{now}}為 抓到今日之後,讓節點產生 今天的一週後,與今天的一週後的下一個禮拜六兩個變數,因此假設今天是 10/6 號,這兩個節點分別為產出 2025-10-13T01:18:07.732-04:00 與 2025-10-19T01:18:07.732-04:00 的變數
這兩個變數有包含詳細時間,會在後面的節點使用時去除,不過這前三個節點,我就可以達成 在固定時間觸發,並設定下週的日期區間
2. AI Agent - 透過 Playwriht 網頁爬蟲使用
這個節點就是這次最重要的部分了,也就是透過 AI 使用 Playwright 工具來抓取 Facebook 頁面資料(類似 F12 把 html 全部 copy 下來),並且把這些資料丟給下一個 AI Agent 節點做 filter 以及整理。
Chat Model
這邊我直接使用 Gemini 2.5 Flash(note: 2025-10-05)
Memory
說明一下,由於 n8n 流程上 AI Agent 表定只是一個執行節點,沒辦法像 ChatGPT 那樣有對話視窗以及儲存區,掛用一個 Simple Memory,我是把 Session ID 這個變數使用 {{now}}-1,反正只要不重複就好
MCP Server
在 n8n 的 AI Agent 中,沒辦法如同一般 Claude Desktop 或 Roo Code 那樣設定 local 的 MCP Server access 方法,如 docker 或 npm,因此他僅能夠透過外部存取 remote 的方式來使用。
因此我的規劃是要架設一個 Playwright MCP 服務,並且讓我的 n8n 可以存取到這個服務,由於我的 n8n 是用 docker 所建立起來,因此我的想法就簡單多了 - 在同樣的 docker 環境中建立一個 Playwright MCP server。直接透過 docker 內網讓兩個連線。
以下是我建立 Playwright MCP server 的 docker compose 檔案
services:
playwright-mcp:
image: mcr.microsoft.com/playwright/mcp
container_name: playwright-mcp
restart: unless-stopped
ports:
- "8931:8931"
networks:
- net #要跟我 n8n 使用同一個網路
command:
- --host
- "0.0.0.0"
- --port
- "8931"
- --headless
- --no-sandbox
shm_size: 1g
networks:
net:
external: true
我有點忘了相關的細節,重點是在要把自己的 host 叫做 0.0.0.0(local),這樣才會存取。
Docker 建立起來之後,理論上同一個 docker 網路的 n8n 就可以存取這個 MCP Server,在 AI Agent 節點的 SSE endpoint 中填入你的 playwright mcp server 服務 http://{{localhostip}}:8931/sse
這邊要注意是要填入你的 server ip,如果填入 localhost 的話 AI Agent 會以為是在 n8n 這個 docker 容器的 localhost。到這邊最困難的技術部份就解決掉了。
AI Agent Prompt 設計
這邊就是最核心的內容,也是我多次修改之後的結果,先給大家看我的 prompt
使用 tool "browser_navigate" 進入網頁 "https://www.facebook.com/粉絲專頁/upcoming_hosted_events"
這是一個 Facebook 粉絲專業的活動頁面,如果碰到 Facebook 要求的登入彈窗,請把視窗關閉,接著直接把目前網頁上資訊全部回傳,不添加任何文字描述,直接回傳 tool 的 response
這樣設計唯一的一個目的是在讓 AI Agent 成為很純粹的爬蟲,除了爬蟲之外不要做任何其他分析行為,這麼做主要有兩個原因
- 讓 AI Agent 任務單一化,任務多個的時候較難保證產出內容
- 如果要 AI Agent 用 MCP 抓資料再分析,會讓上下文拉很長,且每次都會去 read MCP 檔案,消耗 token
以上!就是我這個節點的設計,順利的話會在這個節點產出 Facebook 活動 list 頁面的資訊,並把這串資料傳給後面的 AI 節點做資料清洗。
3. AI Agent - 整理爬蟲資料
如同上面說明,為了讓 AI Agent 的工作內容以及產出單一,在上一個節點進行類似瀏覽網頁抓取資料的行為後,這個節點主要是進行資料的清洗,把我們指定日期區間的活動撈出來,其中 LLM 以及 Simply Memory 設置一樣(但 Simply Memory 我給了一個 {{now}}-2,換一個 ID),然後由於資料是上一個 AI Agent 提供,這節點就不用串 MCP Server 了,因此直接來看 Prompt 設計吧:
以下資料為一個活動列表拆解的網頁爬蟲資訊
「{{ $json.output }}」
1. 從整理的資料中,篩選出日期在 {{ $('1 week').item.json.newDate.substr(0,10) }} 到 {{ $('2 week').item.json.newDate.substr(0,10) }} 之間的活動,要包含頭尾這兩天,並整理以下資訊
- "eventTitle" 演出標題
- "eventDate" 把日期整理為格式 "2025-08-01",要注意由於前面資料抓下來的時間沒有給年份,但其實這些都是今天之後的活動,因此年份至少在 {{ $('1 week').item.json.newDate.substr(0,4) }} 之後,不要寫到前一年
- "eventTime" 顯示為 24 小時制如 "21:00"
- "eventLink" 演出連結
2. 整理之後,請用 text 格式把挑出來的內容整理成以下回覆,並且不要加上任何文字,直接給我 JSON 內容如以下
[{"eventTitle":"xxxx","eventDate":"2025-09-09","eventTime":"21:00","eventLink":"https://xxx"},
{"eventTitle":"xxxx","eventDate":"2025-09-09","eventTime":"21:00","eventLink":"https://xxx"}
]
有幾個重點:
「{{ $json.output }}」在實際 n8n 執行時就是會拋出上一個節點的 json 內容,也就是上一個 AI Agent 給的資料{{ $('1 week').item.json.newDate.substr(0,10) }}這其實就是拿到了我的時間變數,並且用.substr(a,b)來截取字串,擷取就只會拿到 2025-10-13 的部分- 最後限制 AI Agent 的回話很重要,為了要讓他輸出我們可以後續資料請洗的內容,一定要規範他
不要加上任何文字以及直接給JSON,目前測試下來比較聰明的 AI(至少 Gemini 2.5 flash) 能給出我實際要的東西。
這個節點花了滿多時間去處理 Prompt 的設計,算是純粹的用嘴巴資料清洗,但與傳統不一樣的是我們這次順利的把 Facebook 的髒資料洗乾淨成我們要的格式內容。
4. Script 與 Google Sheet - 整理 AI 產出資料寫入 Google Sheet
最後很簡單,我就直接用說明好了,把上一個節點 AI 產出來的資料在用 javascript 清洗一次,目的是把 AI 產出內容中多餘的地方處理掉,留下純的 JSON。
最後拿到乾淨的 JSON ,就可以透過 Google Sheet 節點寫入表單來應用。
成果展示與回顧
寫入到 Google sheet 之後大概是這樣,我有空也會大概晃一下,如果有錯誤或奇怪的地方會手動修正。

目前這個系統我 Run 起來滿喜歡的,關於網站比較多反而是設計以及推廣方面要加強,但對於不用一直手動去更新、key in 演出資料這件事情差滿多的,其中有注意到幾點有趣的事情:
- 由於我的 MCP Server 為 Docker,如果短時間重複 call 會造成 MCP Server 以為是同一個 request,虛擬瀏覽器還沒關閉就直接執行,可能會壞掉或 response error,因此我雖然都是在週日執行,但每個 workflow 會差異大概 15 分鐘。
- 我一週跑一次,大概會花到台幣 $5 元,其實非常的少。
- 真正的問題其實是在許多爵士場館都沒有一個 official 發布演出資訊的地方,特別是沒有官方網站,總體感受起來不夠正式,而我有做出 workflow 的場館已經是至少有在 Facebook 上製作活動連結,許多小場館甚至只會發發文了事,再遭一些就只有限時動態貼文,對於宣傳以及資訊保存很沒有幫助。
以上是我的分享,歡迎大家如果感興趣的話可以來跟我聊聊,或是在你的工作上有需要的話可以跟我合作。