前言
前陣子因為公司的專案需求,Survey 了市面上對於 Browser 操作的相關自動化工具,找到了 Playwright 這個技術框架,後續在測試 AI 以及 MCP 的時候,開始覺得這個 Playwright 能達到的任務與目標實在太強大了,花了點時間研究,這裡做一些推廣給大家知道這個有趣的東西,希望可以給別人一些幫助。
這篇文章會包含以下內容
- Playwright 是什麼
- 本地安裝 Node.js
- 設定 AI Agent MCP Server(Claude Desktop)
- 測試案例 - 網路爬蟲,抓 Facebook 粉專活動列表
1. Playwright 是什麼
Playwright 是微軟所推出的方案,主要用於自動化網頁瀏覽器操作,支持多種瀏覽器並模擬如點擊、輸入、截圖、拖曳等實際在 Web 上面的操作行為,因此很常使用在 end-to-end 的自動化測試,例如什麼網站點 100 次,或是測試搶票之類的操作。
過去這個工具是有門檻的,必須要搭配其他語言使用,然而在 MCP 這個概念出現之後,我們使用軟體的方式就被改變了。而微軟在這波 AI 浪潮中,推出了 Playwright-MCP ,這個將所有 Playwright 的操作封裝,讓 AI Agent 可以透過 MCP 去實際操作網站行為後,我們就開始理解到了 AI 接下來可以代替我們做許多電腦上面的操作,因此接下來我們可以叫 AI 做的事情,就已經遠遠超過只是在聊天界面所進行的對話,例如:
「去OO網站填寫表單」
「在 http://xxx.xxx.xxx 使用帳號密碼 ooo xxx 登入簽到」
「進入 Facebook 某粉專活動列表,找到近期的活動整理給我」
MCP 版本的 Playwright 可以讓我們省去開發精細自動化過程的時間,透過 prompt 來執行需要的操作,這樣的優點是對於那些在標籤、id 會不會同整來防止爬蟲的網站(例如 facebook),可以讓 AI 在每次抓資料後進行解析。而缺點也很明顯,就是一般來說我們很難去完美控制 AI 的內容,且會消耗 Token。
不過呢!透過 Playwright 還是可以幫助我們解決超級多的問題,今天就還是讓我們來試試看在 Local 用自己的 AI Agent ,實踐 Playwright 的操作吧
2. 本地安裝 Node.js
為了要讓 AI Agent 有能力去執行 Playwright,我自己測試下來用 npm 是最穩定以及方便的方法,因此要先請大家去安裝 Node.js 以及 npm,可以依靠 AI 來安裝完成即可。
就這樣!超級簡單
3. 設定 AI Agent MCP Server(Claude Desktop)
接著我們要設定 AI Agent 環境,我自己比較常用的其實是 VSCode 的 RooCode Plugin,這篇文章會使用 Claude Desktop 來操作,來比較接近大家使用 MCP 的情境。
- 下載 Claude Desktop,為了要使用 MCP ,我們需要在 local 安裝 Claude 而不是在雲端使用。
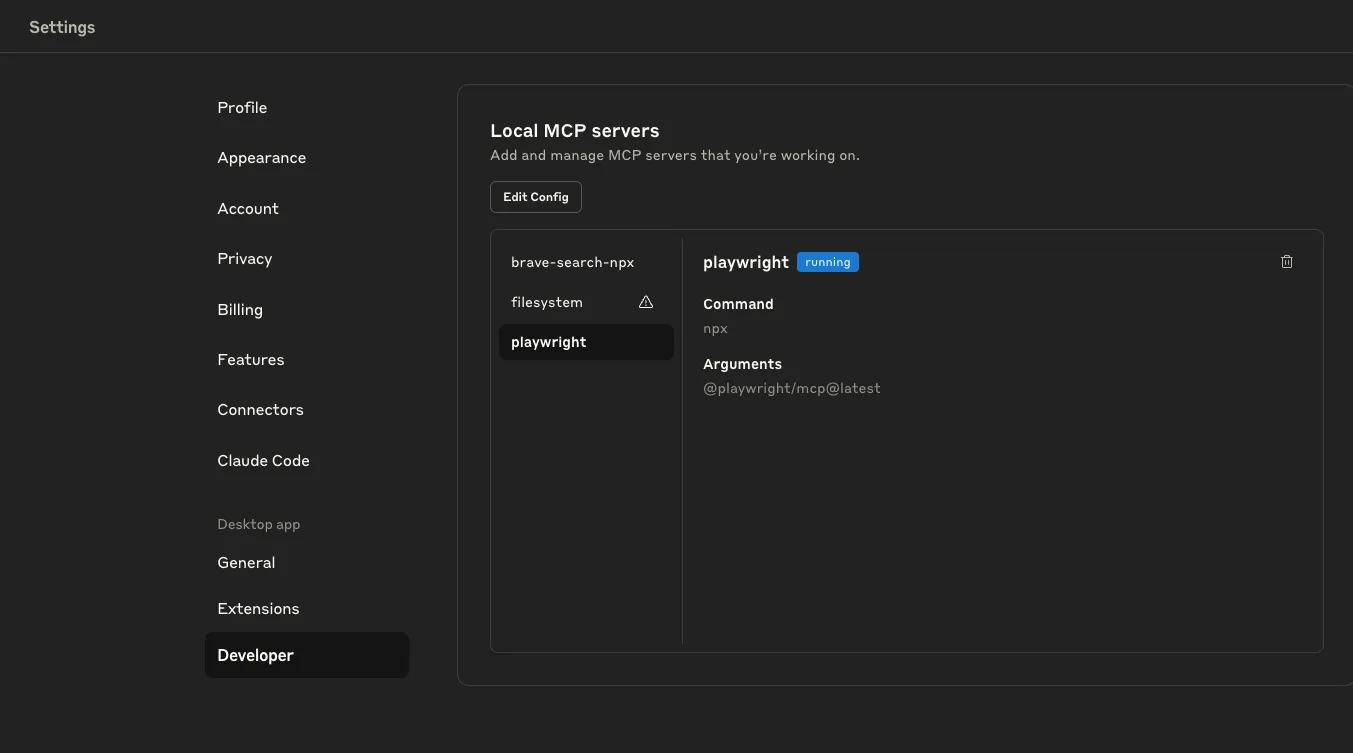
- 在
Setting中,點選Edit Config,直接依照官方 Playwright-MCP 中設定 MCP 的參數,填進去就可以保存退出。
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}
- 重新開啟 Claude ,再進來一次
Setting,順利的話應該會看到如下圖的 playwright 旁邊顯示 Running,而如果沒有的話,可以問問 AI 看是不是 Claude Desktop 沒有吃到 local 的 node js 專案。
- 接著我們回到 Claude 對話畫面,做一個簡單的測試,在這裡我是下了指令
請前往 https://html.onlineviewer.net/ 網頁,並且在畫面中的輸入欄位,輸入 <h1> https://swingyoyo.com</h1><p>我成功用 mcp-playwright 進行瀏覽器操作</p>,讓我們來看看發生了什麼事吧。
我們來解析下發生了什麼事情:
- AI 根據我的訊息,用了 playwright mcp 中的 tool
browser_navigate來前往我給的 html viewer 網頁 - MCP Server 把 tool 執行的 Response 回傳給 AI
- AI 根據 Response ,知道有一個 HTML 輸入匡,因此再呼叫
browser_type來輸入我指定的資訊
由此可理解到,在這邊 AI Agent 就如同一個可以實際操作的人一樣,會根據與 Playwright 的互動,來推進接下來的操作與要做的內容。
4. 測試案例 - 網路爬蟲,抓 Facebook 粉專活動列表
會想要測試這個的原因在於,過往的網路爬蟲方式,對於 Social media 或者有擋爬蟲設定的網站都沒辦法進行,首先是由於網頁有設置反爬蟲,再來許多標籤或 id 會動態更換,以至於根本沒辦法穩定地爬到資料。
但今天 Playwright 不一樣,他等於是用瀏覽器實際前往之後,用類似 copy 的方法把看到的文字取得下來,因此只要 AI Agent 透過 MCP Server 的能力,就可以直接取得網頁上看到的文字,而不用考慮反爬蟲的問題。
因此我們就來測試一個情境 抓取 Facebook 公開社團中,一個禮拜的活動資訊,我們就先以這個 Taiwan 爵士樂演出情報 FB 社團來測試,以下為這個情境的 Prompt,而由於我自己透過無痕操作時,有注意到 FB 會跳出屏蔽登入畫面,因此也特別告訴 AI 這件事情。
以下為我所寫的 Prompt:
今天是 2025.08.15 日,請抓取這個 Facebook 活動社團中,接下來兩個禮拜的活動,並整理給我 [eventTitle], [eventDate], [eventTime]
操作過程中有如果碰到 FB 屏蔽要求登入畫面,請點選 "X" 關閉
https://www.facebook.com/groups/2529837830632076/events
接著我們來看看實際 Claude 執行的畫面吧
可以看到 Claude 操作時很順利的把這些資訊都取得下來,並且整理給我,確實解決了傳統爬蟲會碰到的問題。
結語
這篇主要是一個敲門磚,讓大家體會以及感受到 Playwright 的能力,以及在 AI Agent 中如何使用它來操作瀏覽器,後續會再寫一篇與 n8n 結合的自動化設計的方式。